OpenClaw Autonomy: Why the Orchestration Layer Matters More Than Claude Code or Codex
I stopped thinking of Claude Code or Codex as the machine. OpenClaw autonomy is the machine. That shift matters because the thing that keeps a solo operator sane is not a clever model call; it is the layer that handles intake, routing, context, execution, verification, and handoff without turning every job into a one-off script. OpenClaw autonomy is what keeps that system from depending on one tool’s interface or one model’s mood.
That is the part people miss when they talk about AI tools like they are the whole stack. Claude Code is useful. Codex is useful. But if I have to rebuild the workflow every time a model changes, the system is fragile. I want the opposite: one orchestration layer, interchangeable workers, and enough structure that I can swap the worker without rewriting the process.
I wrote a similar breakdown of the stack shape in Hybrid Agentic Stack Blueprint. This post is the cleaner version of that idea: OpenClaw owns the workflow, and Claude Code or Codex are cogs inside it.
Why OpenClaw autonomy is about owning the workflow, not the model
The first mistake is treating the model as the center of gravity. The model is only one step in the chain. The real work starts before the prompt and ends after the output has been checked. If a system cannot manage that whole path, it is not autonomous. It is just chat with extra steps.
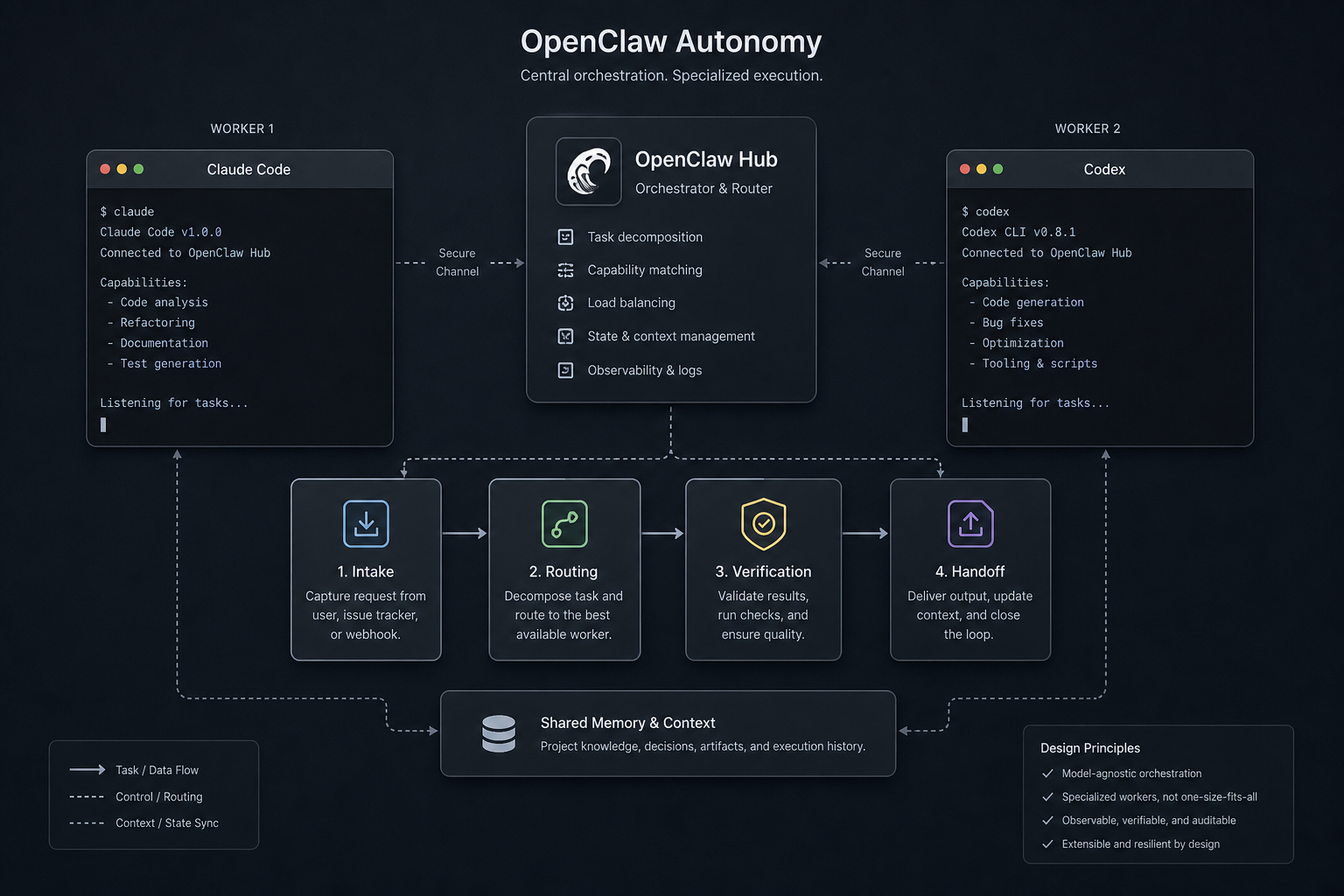
OpenClaw is the layer that makes the whole thing behave like a system instead of a conversation. It decides what comes in, where it goes, what context it gets, what tool runs, what gets verified, and what gets handed off next. That is why I care about OpenClaw autonomy. It gives me ownership of the parts that matter when the stack is working and when it breaks.
This is also the reason vendor independence is not some abstract principle. It is operational. If the orchestration layer is mine, I am not tied to one tool vendor’s UI, pricing, or product direction. I can keep the workflow and change the worker.
What OpenClaw actually owns in the stack
The useful version of agent systems is not “ask the AI and hope.” It is a sequence. OpenClaw sits in that sequence and keeps it honest.
- Intake: a brief, task, or trigger comes in with enough detail to do real work.
- Routing: the job goes to the right worker based on the task, not the hype.
- Context: the worker gets the files, notes, and history it actually needs.
- Execution: the worker runs commands, edits files, or writes output.
- Verification: the result gets checked before anyone treats it as done.
- Handoff: the output gets stored, passed on, or queued for the next step.
That is the boring part, and that is why it works. Most AI demos stop at generation. Real work starts after generation, when you have to decide whether the output is correct, whether the task is complete, and what should happen next. OpenClaw handles that layer so I do not have to glue it together every time.
This is also where a lot of tool talk gets shallow. People compare front-end features and forget that the workflow is the product. I do not care if a worker is flashy if it cannot live inside a repeatable process.
Claude Code is a worker, and it is a good one
Claude Code earns its place because it is comfortable in the terminal and inside a codebase. Anthropic’s own overview describes it as a terminal-based agentic coding tool that can edit files, run tests, and create commits. That is exactly the kind of worker I want available when the job is code-heavy and local context matters. Claude Code overview
That does not make Claude Code the machine. It makes it a strong hand inside the machine. I want a worker like that when the task is close to the repo, when the command line matters, and when the job benefits from direct file access instead of a separate web app sitting on top of everything.
Claude Code also fits the shape of a real operating system for work because it is not just generating text. It can act. That matters. A model that can reason but cannot touch the repo is only doing part of the job. A worker that can read, edit, test, and commit becomes useful in a much narrower, more practical sense.
That is why I do not treat Claude Code as a rival to OpenClaw. I treat it as one of the workers OpenClaw can dispatch when the task calls for it.
Codex is another worker, and the difference matters
OpenAI frames Codex as a coding agent built for real engineering work, with support for multi-agent workflows, cloud environments, and parallel task execution. That shape is different from Claude Code’s terminal-first feel, and that difference is useful. It means I can pick the worker that fits the job instead of forcing every job through the same tool.
That is the part worth paying attention to. Codex is not interesting because it exists. It is interesting because it expands the set of jobs the orchestration layer can send out. If one worker is better for cloud-based parallel work and another is better for local repo work, OpenClaw can treat that as routing logic instead of a philosophical decision.
That is what vendor independence looks like in practice. Not ideology. Not a manifesto. Just a stack that keeps moving when the worker changes.
The mistake is thinking that switching tools means starting over. It does not, if the workflow lives above the tool. If the job definition, context packaging, and verification steps are stable, the worker can change without tearing the system apart.
What changes when the worker changes
This is the real test. If Claude Code disappears tomorrow, do I lose the workflow? If Codex changes price or direction, do I have to rethink the whole stack? If the answer is yes, I built around the wrong layer.
With OpenClaw owning the flow, the answer should be no. The intake stays the same. The routing stays the same. The context file stays the same. The verification step stays the same. The handoff stays the same. Only the worker changes.
That matters because model and platform churn is normal now. Pricing changes. Interfaces change. Terms change. Feature sets change. If I can swap Claude Code for Codex or Codex for something else without redoing the system, I am less exposed to that churn.
I do not want my business logic to depend on whichever company is having a good quarter. I want the business logic to live in the orchestration layer I own.
A concrete example of how I would run it
Say I get a new task: update a long-form post, clean up the structure, and verify the links. OpenClaw takes the intake and stores the brief. It routes the task to Claude Code if the work is repo-centric and needs direct file edits. It packages the relevant context so the worker does not have to guess. Then it runs the verification step and checks the handoff before the job closes.
If the task is better suited to a different worker, OpenClaw can send it there instead. Maybe the job benefits from Codex because it wants a cloud environment, parallel work, or a different execution style. The point is not that one tool is better in every case. The point is that the control plane is stable while the worker is flexible.
That is the pattern I want on my side of the screen. Not one giant tool that tries to do everything. A control layer. A worker. A check. A handoff. Repeat.
That is also why I like talking about OpenClaw autonomy instead of just “using AI agents.” The phrase is more precise. It describes ownership. It describes separation of concerns. It describes a system you can keep running even when one part changes.
The part that matters most is verification
Execution is easy to admire. Verification is what keeps the system useful. If a worker changes files but no one checks the result, the automation is just fast at making new problems. OpenClaw matters because it keeps verification in the loop instead of treating success as assumed.
That is the discipline I want in any agent stack. Did the task actually finish? Did the file change land? Did the output match the brief? Did the next step get handed off cleanly? Those are the questions that make autonomy real.
It is the same reason I do not trust demos that stop at the first pretty answer. A real stack has to survive bad inputs, partial work, and a worker that needs correction. If the system can handle that, it is useful. If it cannot, it is just a polished failure. OpenClaw autonomy is what keeps that standard in place.
If I were building from scratch
I would build around the orchestration layer first. That means I would define the intake format, the routing rules, the context package, the verification checklist, and the handoff format before I cared which worker was running inside it. Then I would plug Claude Code or Codex into the machine where it fit best.
That order matters. Most people do it backward. They pick a shiny model or coding agent, then they build the process around whatever the tool happens to support. That is how you end up locked into a workflow you did not really design.
OpenClaw autonomy flips that around. The process comes first. The worker comes second. That is the only order that gives me room to adapt later.
If I had to sum it up in one line: build the machine once, then swap the cogs as needed.
What this is not
This is not an argument that Claude Code is bad. It is not an argument that Codex is bad. Both are useful. Both deserve their place. The point is narrower than that: do not confuse a good worker with the system that owns the work.
This is also not a claim that autonomy means no human judgment. It does not. The point of the orchestration layer is to reduce the amount of repeated manual work, not to delete the operator. A good system still needs someone who can decide what should be automated, what should be checked, and what should stop.
That is the line I keep coming back to. The stack should make me faster without making me disposable. It should give me room to move without making me dependent on one vendor’s favorite shape of work.
The bottom line
OpenClaw autonomy is worth caring about because it keeps the valuable part of the stack under your control. Claude Code and Codex are workers. OpenClaw is the machine that knows how to use them.
If I am choosing where to build, I build around the orchestration layer. That gives me room to route work, change tools, and keep moving when the model landscape shifts again. That is the practical version of vendor independence. Not theory. Not hype. Just a system that still works after the shiny part changes.
That is the version I would rather bet on, because OpenClaw autonomy keeps the control plane in my hands.